Graham
| This site replaces the former Compute Canada documentation site, and is now being managed by the Digital Research Alliance of Canada. Ce site remplace l'ancien site de documentation de Calcul Canada et est maintenant géré par l'Alliance de recherche numérique du Canada. |
| Availability: In production since June 2017 |
| Login node: graham.alliancecan.ca |
| Globus endpoint: computecanada#graham-globus |
| Data transfer node (rsync, scp, sftp,...): gra-dtn1.alliancecan.ca |
Graham is a heterogeneous cluster, suitable for a variety of workloads, and located at the University of Waterloo. It is named after Wes Graham, the first director of the Computing Centre at Waterloo.
The parallel filesystem and external persistent storage (called "NDC-Waterloo" in some documents) are similar to Cedar's. The interconnect is different and there is a slightly different mix of compute nodes.
It is entirely liquid cooled, using rear-door heat exchangers.
Site-specific policies[edit]
- By policy, Graham's compute nodes cannot access the internet. If you need an exception to this rule, contact technical support with the following information:
IP: Port/s: Protocol: TCP or UDP Contact: Removal Date:
On or after the removal date we will follow up with the contact to confirm if the exception is still required.
- Crontab is not offered on Graham.
- Each job on Graham should have a duration of at least one hour (five minutes for test jobs) and no more than 168 hours (seven days).
- A user cannot have more than 1000 jobs, running and queued, at any given moment. An array job is counted as the number of tasks in the array.
Storage[edit]
| Home space 133TB total volume |
|
| Scratch space 3.2PB total volume Parallel high-performance filesystem |
|
| Project space 16PB total volume External persistent storage |
High-performance interconnect[edit]
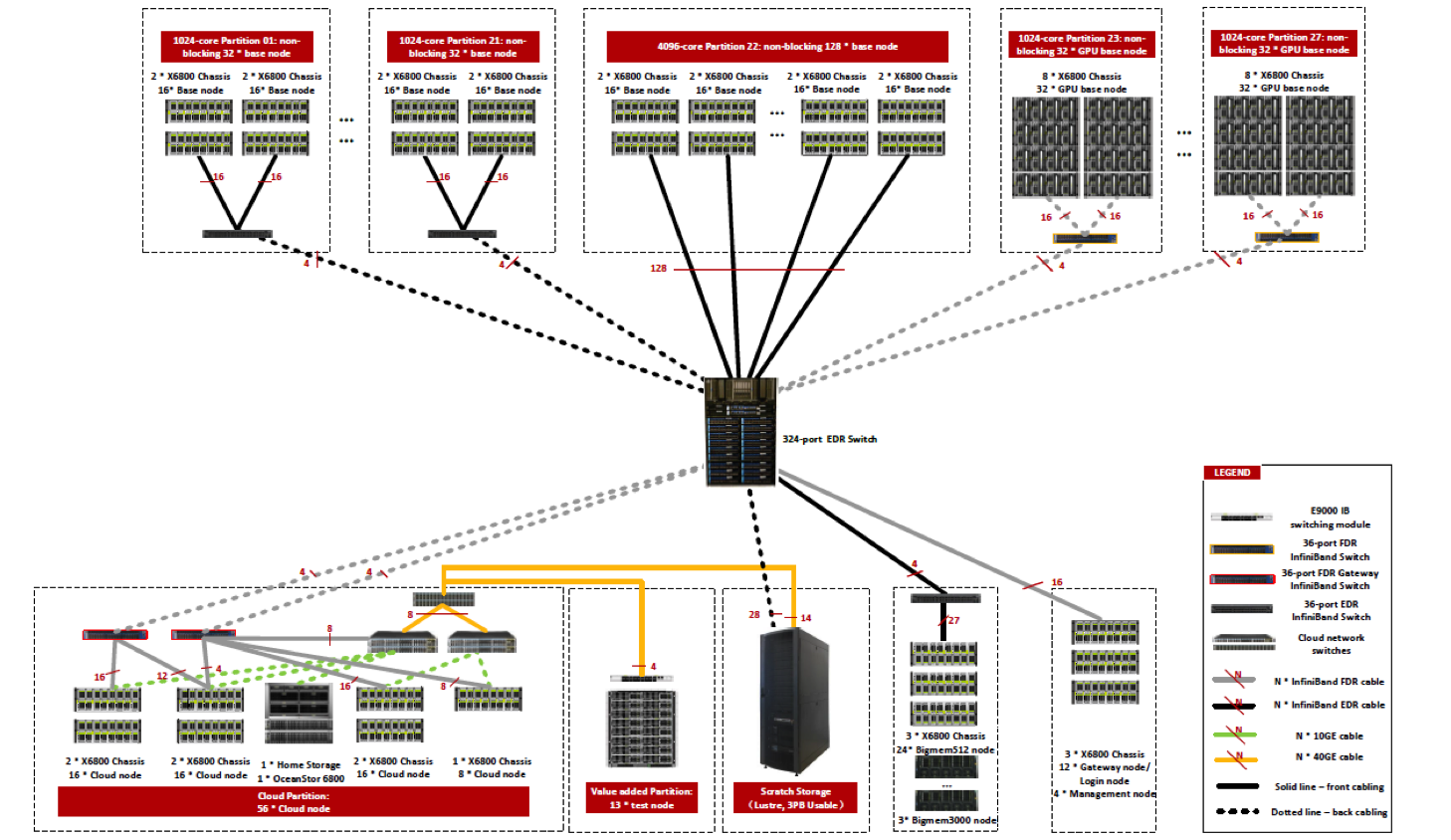
Mellanox FDR (56Gb/s) and EDR (100Gb/s) InfiniBand interconnect. FDR is used for GPU and cloud nodes, EDR for other node types. A central 324-port director switch aggregates connections from islands of 1024 cores each for CPU and GPU nodes. The 56 cloud nodes are a variation on CPU nodes, and are on a single larger island sharing 8 FDR uplinks to the director switch.
A low-latency high-bandwidth Infiniband fabric connects all nodes and scratch storage.
Nodes configurable for cloud provisioning also have a 10Gb/s Ethernet network, with 40Gb/s uplinks to scratch storage.
The design of Graham is to support multiple simultaneous parallel jobs of up to 1024 cores in a fully non-blocking manner.
For larger jobs the interconnect has a 8:1 blocking factor, i.e., even for jobs running on multiple islands the Graham system provides a high-performance interconnect.
Graham high performance interconnect diagram
{kind=link}
Visualization on Graham[edit]
Graham has dedicated visualization nodes available at gra-vdi.alliancecan.ca that allow only VNC connections. For instructions on how to use them, see the VNC page.
Node characteristics[edit]
A total of 41,548 cores and 520 GPU devices, spread across 1,185 nodes of different types; note that Turbo Boost is activated for the ensemble of Graham nodes.
| nodes | cores | available memory | CPU | storage | GPU |
|---|---|---|---|---|---|
| 903 | 32 | 125G or 128000M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | 960GB SATA SSD | - |
| 24 | 32 | 502G or 514500M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | 960GB SATA SSD | - |
| 56 | 32 | 250G or 256500M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | 960GB SATA SSD | - |
| 3 | 64 | 3022G or 3095000M | 4 x Intel E7-4850 v4 Broadwell @ 2.1GHz | 960GB SATA SSD | - |
| 160 | 32 | 124G or 127518M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | 1.6TB NVMe SSD | 2 x NVIDIA P100 Pascal (12GB HBM2 memory) |
| 7 | 28 | 187G or 191840M | 2 x Intel Xeon Gold 5120 Skylake @ 2.2GHz | 4.0TB NVMe SSD | 8 x NVIDIA V100 Volta (16GB HBM2 memory).
Note that one node is only populated with 6 GPUs. |
| 2 | 40 | 377G or 386048M | 2 x Intel Xeon Gold 6248 Cascade Lake @ 2.5GHz | 5.0TB NVMe SSD | 8 x NVIDIA V100 Volta (32GB HBM2 memory),NVLINK |
| 6 | 16 | 187G or 191840M | 2 x Intel Xeon Silver 4110 Skylake @ 2.10GHz | 11.0TB SATA SSD | 4 x NVIDIA T4 Turing (16GB GDDR6 memory) |
| 30 | 44 | 187G or 191840M | 2 x Intel Xeon Gold 6238 Cascade Lake @ 2.10GHz | 5.8TB NVMe SSD | 4 x NVIDIA T4 Turing (16GB GDDR6 memory) |
| 136 | 44 | 187G or 191840M | 2 x Intel Xeon Gold 6238 Cascade Lake @ 2.10GHz | 879GB SATA SSD | - |
| 1 | 128 | 2000G or 2048000M | 2 x AMD EPYC 7742 | 3.5TB SATA SSD | 8 x NVIDIA A100 Ampere |
| 2 | 32 | 256G or 262144M | 2 x Intel Xeon Gold 6326 Cascade Lake @ 2.90GHz | 3.5TB SATA SSD | 4 x NVIDIA A100 Ampere |
| 11 | 64 | 128G or 131072M | 1 x AMD EPYC 7713 | 1.8TB SATA SSD | 4 x NVIDIA RTX A5000 Ampere |
Most applications will run on either Broadwell, Skylake, or Cascade Lake nodes, and performance differences are expected to be small compared to job waiting times. Therefore we recommend that you do not select a specific node type for your jobs. If it is necessary, for CPU jobs there are only two constraints available, use either --constraint=broadwell or --constraint=cascade. See how to specify the CPU architecture.
Best practice for local on-node storage is to use the temporary directory generated by Slurm, $SLURM_TMPDIR. Note that this directory and its contents will disappear upon job completion.
Note that the amount of available memory is less than the "round number" suggested by hardware configuration. For instance, "base" nodes do have 128 GiB of RAM, but some of it is permanently occupied by the kernel and OS. To avoid wasting time by swapping/paging, the scheduler will never allocate jobs whose memory requirements exceed the specified amount of "available" memory. Please also note that the memory allocated to the job must be sufficient for IO buffering performed by the kernel and filesystem - this means that an IO-intensive job will often benefit from requesting somewhat more memory than the aggregate size of processes.
GPUs on Graham[edit]
Graham contains Tesla GPUs from three different generations, listed here in order of age, from oldest to newest.
- P100 Pascal GPUs
- V100 Volta GPUs (including 2 nodes with NVLINK interconnect)
- T4 Turing GPUs
P100 is NVIDIA's all-purpose high performance card. V100 is its successor, with about double the performance for standard computation, and about 8X performance for deep learning computations which can utilize its tensor core computation units. T4 Turing is the latest card targeted specifically at deep learning workloads - it does not support efficient double precision computations, but it has good performance for single precision, and it also has tensor cores, plus support for reduced precision integer calculations.
Pascal GPU nodes on Graham[edit]
These are Graham's default GPU cards. Job submission for these cards is described on page: Using GPUs with Slurm. When a job simply request a GPU with --gres=gpu:1 or --gres=gpu:2, it will be assigned to any type of available GPU. If you require a specific type of GPU, please request it. As all Pascal nodes have only 2 P100 GPUs, configuring jobs using these cards is relatively simple.
Volta GPU nodes on Graham[edit]
Graham has a total of 9 Volta nodes. In 7 of these, four GPUs are connected to each CPU socket (except for one node, which is only populated with 6 GPUs, three per socket). The other 2 have high bandwidth NVLINK interconnect.
The nodes are available to all users with a maximum job duration of seven days.
Following is an example job script to submit a job to one of the nodes (with 8 GPUs). The module load command will ensure that modules compiled for Skylake architecture will be used. Replace nvidia-smi with the command you want to run.
Important: You should scale the number of CPUs requested, keeping the ratio of CPUs to GPUs at 3.5 or less on 28 core nodes. For example, if you want to run a job using 4 GPUs, you should request at most 14 CPU cores. For a job with 1 GPU, you should request at most 3 CPU cores. Users are allowed to run a few short test jobs (shorter than 1 hour) that break this rule to see how your code performs.
The two newest Volta nodes have 40 cores so the number of cores requested per GPU should be adjusted upwards accordingly, i.e. you can use 5 CPU cores per GPU. They also have NVLINK, which can provide huge benefits for situations where memory bandwidth between GPUs is the bottleneck. If you want to use one of these NVLINK nodes, you should request it directly by adding the --constraint=cascade,v100 parameter to the job submission script.
Single-GPU example:
#!/bin/bash
#SBATCH --account=def-someuser
#SBATCH --gres=gpu:v100:1
#SBATCH --cpus-per-task=3
#SBATCH --mem=12G
#SBATCH --time=1-00:00
module load arch/avx512 StdEnv/2018.3
nvidia-smi
Full-node example:
#!/bin/bash
#SBATCH --account=def-someuser
#SBATCH --nodes=1
#SBATCH --gres=gpu:v100:1
#SBATCH --cpus-per-task=3
#SBATCH --mem=12G
#SBATCH --time=1-00:00
module load arch/avx512 StdEnv/2018.3
nvidia-smi
The Volta nodes have a fast local disk, which should be used for jobs if the amount of I/O performed by your job is significant. Inside the job, the location of the temporary directory on fast local disk is specified by the environment variable $SLURM_TMPDIR. You can copy your input files there at the start of your job script before you run your program and your output files out at the end of your job script. All the files in $SLURM_TMPDIR will be removed once the job ends, so you do not have to clean up that directory yourself. You can even create Python virtual environments in this temporary space for greater efficiency. Please see the information on how to do this.
Turing GPU nodes on Graham[edit]
The usage of these nodes is similar to using the Volta nodes, except when requesting them, you should specify:
--gres=gpu:t4:2
In this example, two T4 cards per node are requested.
Ampere GPU nodes on Graham[edit]
The usage of these nodes is similar to using the Volta nodes, except when requesting them, you should specify:
--gres=gpu:a100:2
or
--gres=gpu:a5000:2
In this example, two Ampere cards per node are requested.